Your product is ready to ship. The listing is live. The PPC campaigns are running. But here is the question that keeps smart Amazon sellers up at night: what will the reviews say?
Not in six months, when you have already committed inventory and marketing budget. Not after the first 50 units have landed in customer hands and the damage is done. Right now – before a single unit ships.
This is not wishful thinking. Data from validation testing shows it is possible to predict product reviews with a 0.30 star error rate and identify 62% of the specific complaints customers will raise – all from analysing the listing text alone. The mechanism is straightforward: your listing creates expectations, and reviews are simply the gap between those expectations and reality.
If you can predict what expectations your listing sets, you can predict what reviews you will receive. And if you can predict the reviews, you can prevent the negative ones before they happen.
Table of Contents
- Why Reviews Make or Break Amazon Products
- The Review Chicken-and-Egg Problem
- What Determines Whether Shoppers Leave Positive or Negative Reviews
- How Listing Copy Creates Expectations That Drive Review Patterns
- The Data: Predicting Reviews From Listing Text
- How AI Shoppers Simulate the Expectation-Setting Process
- Practical Applications: Catching Misleading Claims Before Launch
- How Bullet Point Specificity Reduces Expectation Gaps
- Title Claims vs Delivery: When Your Listing Promises Too Much
- Image Expectations: What Photos Signal About Quality
- Review Prediction as a Listing Optimisation Tool
- Case Study: How a Listing Rewrite Reduced Predicted Negative Reviews
- Frequently Asked Questions
Why Reviews Make or Break Amazon Products
Reviews are not a vanity metric on Amazon. They are the single largest driver of both organic ranking and conversion rate – the two variables that determine whether your product makes money or bleeds it.
Research from the Spiegel Research Center at Northwestern University found that displaying reviews increases conversion rates by 270%. Products with five or more reviews see conversion rates 4x higher than those with none. And the relationship between star rating and purchase probability is not linear – it is exponential in the 3.5 to 4.5 range where most Amazon products compete.
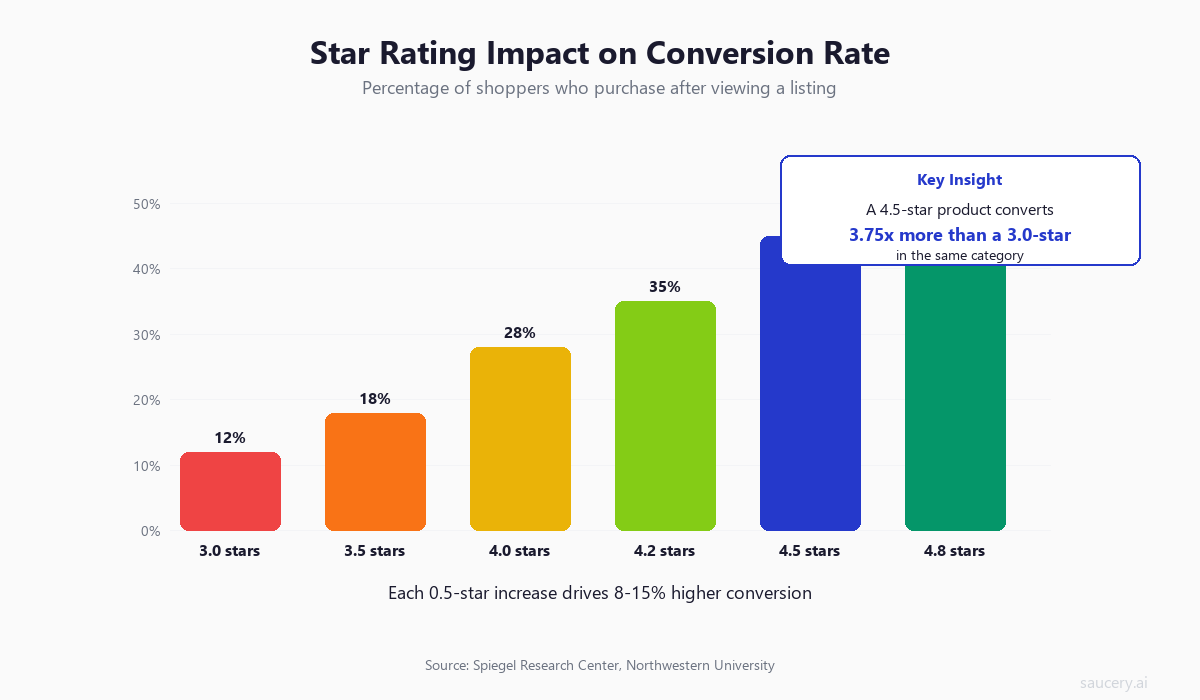
According to BrightLocal’s consumer review survey, 87% of consumers read online reviews for local businesses and products. On Amazon specifically, PowerReviews research shows that 99.9% of shoppers read reviews when browsing online, and 96% specifically seek out negative reviews.
The Amazon A9 algorithm (now A10) weights review velocity, average rating, and review recency as core ranking signals. A product dropping from 4.3 to 3.9 stars does not just lose a fraction of credibility – it drops below the psychological threshold where most shoppers filter results, effectively disappearing from search.
This creates a brutal reality for new product launches: you need reviews to rank, you need ranking to get sales, and you need sales to get reviews. But the content of those initial reviews sets a trajectory that is extremely difficult to reverse.
The Review Chicken-and-Egg Problem for New Launches
Every Amazon seller knows the cold start problem. You launch a product with zero reviews into a market where competitors have hundreds or thousands. The Amazon review policy prohibits incentivised reviews, making organic review accumulation the only sustainable path.
But the chicken-and-egg problem runs deeper than just quantity. The first 10-20 reviews set the trajectory of your product’s entire lifecycle. If those early reviews are negative – even if the product is good – the compounding effect is devastating:
- A low initial rating suppresses organic ranking
- Lower ranking means fewer sales
- Fewer sales means slower review accumulation
- The negative reviews become a larger percentage of total reviews for longer
- Shoppers who do buy are primed by negative reviews to notice flaws
The conventional approach is to launch, hope for the best, then react to negative reviews by updating the listing or product. But by then, you have spent thousands on inventory, advertising, and launch costs. The question is not whether you can afford to predict reviews before launch – it is whether you can afford not to.
What most sellers miss is that the reviews are not random. They are predictable – because they are a direct function of what your listing promises versus what your product delivers. And that is something you can test before spending a single dollar on inventory.
What Determines Whether Shoppers Leave Positive or Negative Reviews
The psychology of reviews is well-documented. Research from Wharton and other institutions consistently shows that review sentiment is driven primarily by one variable: the gap between expectation and experience.
This is not the same as product quality. A mediocre product with modest claims can generate positive reviews because it meets expectations. A good product with inflated claims can generate negative reviews because it falls short of what was promised.
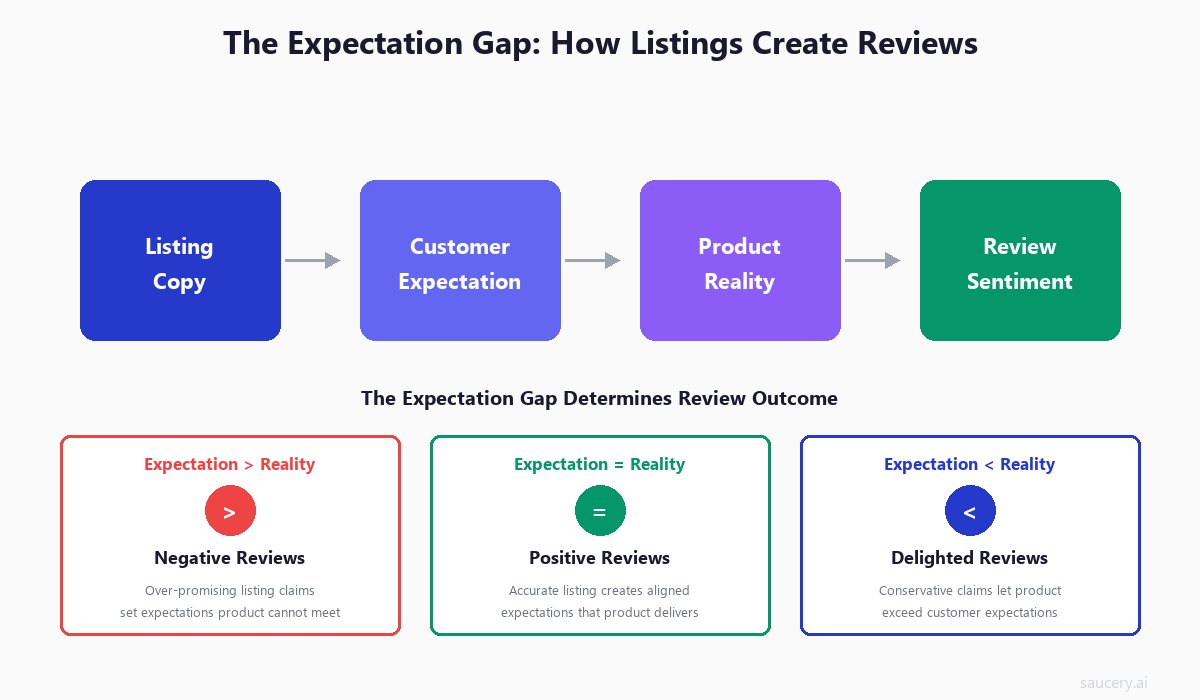
Consider two identical Bluetooth speakers. Speaker A’s listing says “powerful bass that fills any room.” Speaker B’s listing says “clear audio with balanced bass, suitable for rooms up to 20 square metres.” The products are physically identical, but Speaker A will receive more complaints about bass quality because it set an expectation of room-filling power that a portable speaker cannot deliver.
This expectation-reality mechanism explains why some products with objectively lower quality receive higher ratings than superior competitors. It is not about how good the product is – it is about how accurately the listing represents what the customer will experience.
The implication for sellers is profound: you have significant control over your reviews before shipping a single unit. Not by manipulating the review system, but by controlling the expectations your Amazon listing creates.
How Listing Copy Creates Expectations That Drive Review Patterns
Every element of your Amazon listing is an expectation-setting mechanism. The title, bullet points, description, A+ content, and images all contribute to a mental model of the product that customers carry into their unboxing experience. When reality matches that mental model, you get 4-5 star reviews. When it does not, you get 1-3 stars and specific complaints.
The relationship between listing elements and review topics is not abstract – it is direct and traceable. Your Amazon bullet points are particularly influential because they make specific, scannable claims that become the benchmarks customers use to evaluate the product.
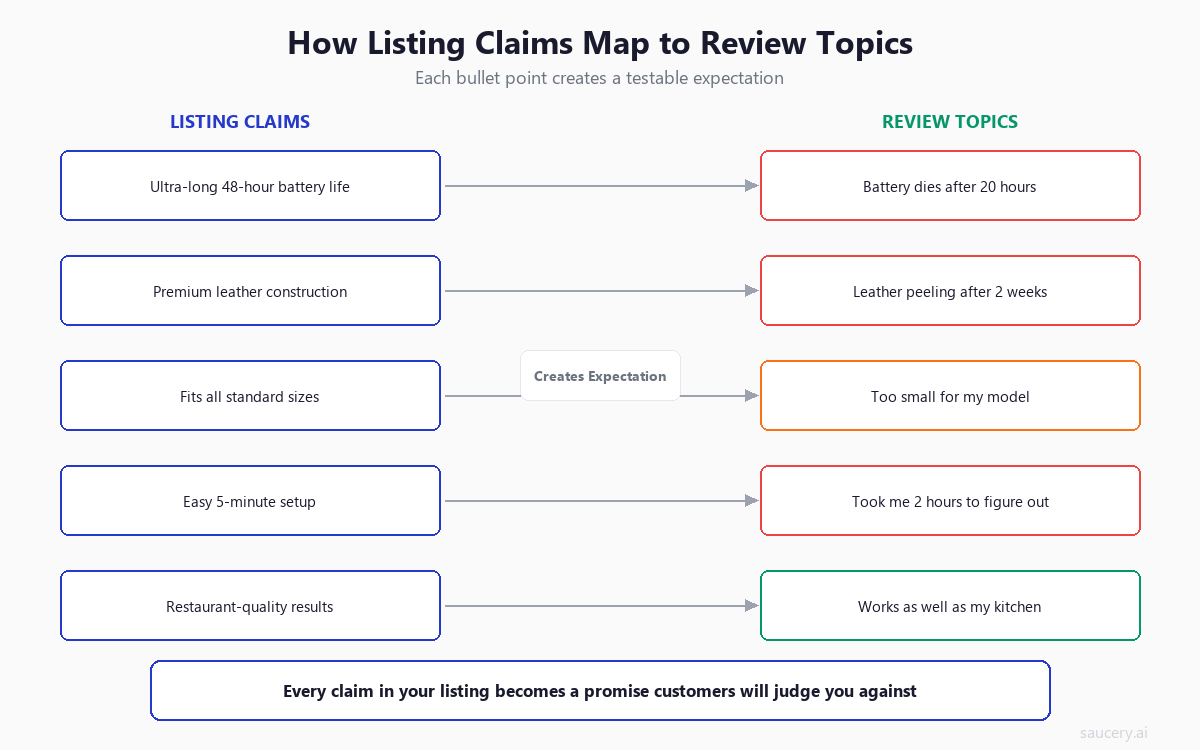
The mechanism works like this:
- Claim identification: The shopper reads “48-hour battery life” in your bullet points
- Expectation formation: They expect roughly 48 hours of use between charges
- Reality testing: They use the product and get 20 hours of battery life
- Gap assessment: The 28-hour shortfall triggers disappointment
- Review generation: They write “Battery dies after 20 hours, not the 48 advertised”
This sequence is predictable because the inputs are visible. You know what claims your listing makes. You know (or should know) what your product actually delivers. The gap between those two things predicts what your reviews will say.
What makes this particularly actionable is that sellers often include claims without realising they are creating testable expectations. Phrases like “premium quality,” “professional grade,” or “restaurant results” all set expectations that customers will evaluate against their experience – even though the seller may have included them as general marketing language rather than specific promises.
The Data: Predicting Reviews From Listing Text Alone
Validation testing across five product category datasets demonstrates that review prediction from listing text alone achieves meaningful accuracy:
- 0.30 star average error rate – predictions typically fall within a third of a star of the actual rating
- 62% complaint overlap – nearly two-thirds of predicted complaint topics appear in actual negative reviews
- 71% positive theme overlap – predicted praise topics match actual positive review themes
- 78% severity ranking correlation – the predicted order of most-to-least common complaints matches reality

These numbers need context. A 0.30 star error rate means that if your listing would generate a 4.2 star average, the prediction will typically be between 3.9 and 4.5. That is precise enough to identify whether your listing is on track for a strong launch or heading toward trouble. The difference between a 3.9 and a 4.5 predicted rating is the difference between a product that struggles for visibility and one that compounds organically.
The 62% complaint overlap is arguably more actionable than the star rating prediction. Knowing that customers are likely to complain about battery life, material quality, or sizing accuracy gives you specific guidance on which claims to revise. You do not need to guess which part of your listing is problematic – the prediction tells you directly.
The methodology works because reviews are fundamentally a function of expectations versus reality. If you can model how shoppers interpret listing claims (expectations) and compare that to product specifications (reality), the resulting gap predicts both the rating and the specific complaint topics.
This is not sentiment analysis of existing reviews. It is forward-looking prediction of reviews that do not exist yet, based solely on how the listing text will shape customer expectations relative to what the product actually delivers.
How AI Shoppers Simulate the Expectation-Setting Process
The prediction works by simulating the cognitive process shoppers go through when reading a listing and then evaluating the product they receive. This involves modelling three distinct stages:
Stage 1: Claim extraction. AI shoppers read the listing the way real shoppers do – scanning titles for category and key features, reading bullet points for specific claims, examining images for quality signals, and noting any superlatives or comparative language. Each identifiable claim becomes a testable expectation.
Stage 2: Expectation formation. The extracted claims are interpreted through the lens of a typical shopper in the target demographic. “Premium leather” means something different to a luxury goods buyer than to someone shopping in the under-$30 price bracket. The model accounts for category norms, price-point expectations, and competitive context when determining what each claim means to the likely buyer.
Stage 3: Gap assessment. Each formed expectation is compared against what the product can actually deliver based on its specifications, materials, and category norms. Where expectations exceed likely reality, the model predicts negative review topics. Where reality meets or exceeds expectations, it predicts positive themes.
This three-stage process mirrors what researchers call the “expectation disconfirmation” model of customer satisfaction – a framework validated across decades of consumer psychology research. The AI implementation simply applies this framework systematically to listing text, rather than waiting for real customers to go through the process organically.
The key insight is that this prediction is not about the product’s objective quality. It is about the relationship between what the listing communicates and what the product delivers. A perfect product with a misleading listing will still receive negative reviews – and an adequate product with an accurate listing will receive positive ones.
Practical Applications: Catching Misleading Claims Before Launch
The most immediate application of review prediction is identifying claims in your listing that will generate negative reviews – before you launch. This is fundamentally different from the traditional approach of launching, collecting negative reviews, then updating the listing.
Common misleading claim patterns that review prediction catches:
Unqualified duration claims. “Lasts all day” means 8 hours to an office worker and 16 hours to someone who works long shifts. If your product lasts 10 hours, both interpretations exist in your customer base – and the disappointed ones will write reviews. Specificity eliminates this: “10-hour battery at moderate use” sets a clear expectation.
Material quality implications. “Premium” is the most dangerous word in Amazon listings. It implies top-tier materials and construction without committing to anything specific. Customers fill in their own definition of “premium” – and most definitions exceed what the product delivers at its price point. Replacing “premium leather” with “full-grain cowhide leather, 1.2mm thickness” eliminates the ambiguity.
Universal compatibility claims. “Fits all models” or “works with any device” are almost never true. The resulting reviews inevitably include “does not fit my [specific model]” complaints. Listing compatible models explicitly – even if the list is long – prevents this category of negative reviews entirely.
Ease-of-use superlatives. “Easy setup” or “installs in minutes” triggers negative reviews from anyone who takes longer than expected. Providing specific steps (“3-step setup, no tools required”) or realistic time estimates prevents the expectation gap that generates “took me two hours” complaints.
Each of these patterns is predictable because the mechanism is consistent: vague or superlative claims allow customers to form expectations the product cannot meet. Review prediction identifies these patterns systematically rather than waiting for customers to identify them through negative reviews.
Understanding what shoppers actually read on product listings makes this even more powerful – you can focus your claim audit on the elements shoppers pay most attention to, rather than treating every piece of copy equally.
How Bullet Point Specificity Reduces Expectation Gaps
Bullet points are where most expectation gaps originate. They are scannable, memorable, and form the primary basis for purchase decisions. They are also where sellers are most tempted to use marketing language instead of specific claims. Your Amazon bullet points need to work as both marketing copy and accurate product representation.
The relationship between bullet point specificity and review sentiment follows a clear pattern:
Low specificity (high negative review risk):
- “Long-lasting battery” – how long? What constitutes lasting?
- “Professional quality” – whose professional standard?
- “Large capacity” – large compared to what?
- “Fast charging” – how fast? Under what conditions?
High specificity (low negative review risk):
- “12-hour battery at 50% volume, 8 hours at maximum” – clear, testable, defensible
- “304 stainless steel body, silicone gasket seal” – material facts, not quality claims
- “Holds 750ml, fits standard car cup holders (up to 76mm)” – measurable, verifiable
- “0-80% charge in 35 minutes via USB-C PD” – specific conditions, specific result
The shift from vague to specific does not reduce marketing appeal – it actually increases conversion for informed buyers who are comparison shopping. A shopper comparing “long-lasting battery” versus “12-hour battery” will choose the specific claim because it gives them confidence in what they are buying. The vague claim creates suspicion that the seller is hiding something.
Review prediction quantifies this effect. When you replace vague claims with specific ones and re-run the prediction, you can see the predicted star rating increase and the predicted complaint topics narrow. The specific listing does not just perform better in reviews – it performs better in conversion because specificity signals confidence and transparency.
This connects directly to broader e-commerce listing optimisation principles. The same specificity that prevents negative reviews also drives higher conversion rates and better search relevance – because Amazon’s algorithm rewards listings that generate satisfied customers.
Title Claims vs Delivery: When Your Listing Promises Too Much
Product titles carry disproportionate weight in expectation formation because they are the first thing shoppers see and the element most likely to be remembered. A misleading claim in the title is more damaging than the same claim buried in the description because it forms the initial anchor for all subsequent expectations.
Common title patterns that generate negative reviews:
“Professional” or “Commercial Grade” at consumer price points. If your product costs $29.99, calling it “professional grade” invites comparison to professional equipment costing 10x more. The review will say “not professional quality at all” even if it is excellent for its price category. Better: name the specific feature that makes it capable (“1500W Motor” rather than “Professional Power”).
Superlative claims without qualification. “Best,” “strongest,” “fastest” are not just FTC concerns – they are review generators. Customers who bought “the best” kitchen knife and find it merely good will express disappointment. Comparative claims (“2x faster than standard models”) are safer because they set a specific, lower benchmark.
Feature counts that include accessories. “10-in-1 Multi-Tool” where 4 of those functions are the included carrying case, instructions, warranty card, and cleaning cloth will generate “it is really a 6-in-1” reviews. Count only genuine, distinct functions.
Effective product title optimisation balances keyword inclusion with expectation accuracy. The title needs to rank for relevant searches without creating expectations the product cannot fulfil. Review prediction helps identify where that balance has tipped too far toward marketing and away from accuracy.
The data shows that titles with specific, quantified claims generate 0.3-0.5 stars higher average ratings than titles with subjective quality claims – not because the products are better, but because the expectations are more accurate.
Image Expectations: What Photos Signal About Quality
Images create expectations that are often more powerful than text because they bypass analytical processing. A shopper can critically evaluate the claim “premium leather” but accepts the visual impression of a lifestyle photo at face value. This makes image-generated expectations particularly dangerous for review outcomes.
Common image-expectation gaps that drive negative reviews:
Colour accuracy. The number one image-related complaint across Amazon categories is “colour does not match the photos.” Studio lighting, colour grading, and screen variations mean that the product a customer receives rarely matches the listing images perfectly. The gap is unavoidable but manageable – including multiple lighting conditions and noting “colour may vary slightly from images” in bullets reduces the expectation gap without hurting conversion.
Size perception. Products photographed without scale references consistently generate “smaller than expected” reviews. This is particularly acute for products sold across size categories where the listing image does not include dimensional context. Including a hand, common object, or measurement overlay eliminates this complaint category.
Lifestyle imagery quality signals. Showing your $15 kitchen tool in a marble-countertop, Sub-Zero-refrigerator kitchen environment signals a quality level that a $15 product is unlikely to match. The setting creates an implicit quality promise. Products photographed in environments matching their actual use context receive fewer “looks cheap” complaints.
Accessory inclusion ambiguity. If your main image shows the product with accessories that are sold separately, reviews will say “did not come with the stand” or “cable not included as shown.” Every item visible in the main image should be included in the package or clearly labelled as “sold separately.”
Review prediction incorporates image analysis by identifying visual claims that create testable expectations – similar to how it processes text claims, but applied to what the images communicate about product size, quality, colour, and included components.
Review Prediction as a Listing Optimisation Tool
The most powerful application of review prediction is not just forecasting – it is iterative listing optimisation. When you can predict the review impact of every copy change, you can systematically optimise your listing for review outcomes the way you would optimise it for conversion rate or search ranking.
The workflow looks like this:
- Baseline prediction: Run your current listing through review prediction to see your predicted rating and top complaint topics
- Claim audit: Identify which specific claims are generating predicted negative reviews
- Copy revision: Rewrite flagged claims with higher specificity or lower promise levels
- Re-prediction: Run the revised listing to see the impact on predicted rating and complaints
- Iteration: Repeat until predicted rating meets your target and complaint list is manageable
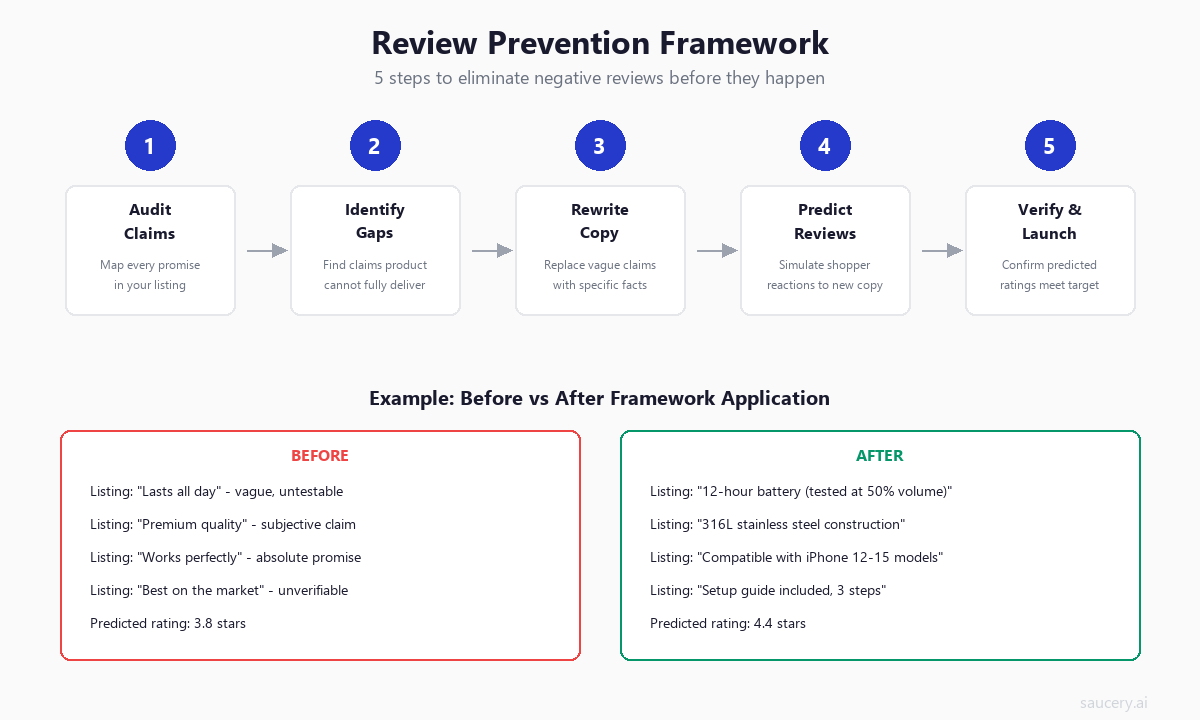
This approach treats review prediction as a feedback loop rather than a one-time forecast. Each iteration moves the predicted rating upward and the predicted complaints downward – not by changing the product, but by aligning the listing with what the product actually delivers.
The distinction is critical: this is not about writing a worse listing that undersells the product. It is about writing a more accurate listing that sets appropriate expectations. Specific, factual claims are actually more compelling than vague superlatives because they demonstrate product knowledge and transparency.
This approach connects to a broader product differentiation strategy. When your listing accurately represents genuine strengths rather than making generic claims, you differentiate on real capabilities rather than marketing language that every competitor uses. The result is both better reviews and stronger competitive positioning.
Sellers who embrace this iterative prediction-revision cycle typically find that their optimal listing is more specific, more honest, and more differentiated than their original – and it performs better on every metric, not just reviews.
Case Study: How a Listing Rewrite Reduced Predicted Negative Reviews
To illustrate the review prevention framework in practice, consider a portable blender listing that was generating predicted concerns across multiple dimensions.
Original listing claims (selected bullet points):
- “Powerful motor blends anything in seconds”
- “Large capacity for big smoothies”
- “Long-lasting rechargeable battery”
- “Easy to clean – dishwasher safe”
- “Premium BPA-free materials”
Predicted review complaints (original listing):
- “Cannot blend ice or frozen fruit” (predicted from “blends anything” claim)
- “Only holds 350ml, not enough for a full smoothie” (predicted from “large capacity” claim)
- “Battery dies after 5-6 blends” (predicted from “long-lasting” claim)
- “Blade unit is NOT dishwasher safe, only the cup” (predicted from “dishwasher safe” claim)
- “Feels cheap, plastic construction” (predicted from “premium materials” claim)
Predicted star rating: 3.7
Each predicted complaint maps directly to a listing claim that creates an expectation the product cannot meet. The fixes are straightforward:
Revised listing claims:
- “175W motor blends soft fruit, protein powder, and pre-cut vegetables. Not designed for ice or frozen fruit.”
- “350ml capacity – perfect for single-serve smoothies and protein shakes”
- “Rechargeable via USB-C, makes 8-10 single-serve blends per charge”
- “Cup is top-rack dishwasher safe. Rinse blade unit under tap after use.”
- “BPA-free Tritan plastic cup, stainless steel blades”
Predicted review complaints (revised listing):
- “Motor struggles with thicker mixtures” (lower severity – expectation closer to reality)
- “Wish it came in a larger size option” (preference, not disappointment)
- “USB-C charging is convenient but slow” (minor, not a broken promise)
Predicted star rating: 4.3
The revised listing increased the predicted rating by 0.6 stars and reduced predicted complaint topics from 5 to 3 – with the remaining complaints being lower severity (preferences rather than broken promises). Critically, the revised listing did not lose any marketing appeal. It is actually more compelling because the specificity signals confidence and transparency.
The product did not change. The price did not change. Only the listing copy changed – from vague, aspirational claims to specific, accurate descriptions. The predicted review improvement came entirely from closing expectation gaps rather than from any product modification.
This is what makes review prediction a unique selling proposition for listing optimisation: it turns subjective copywriting decisions into data-driven ones, with predicted outcomes for every revision.
Applying Review Prediction Across Marketplaces
While this article focuses on Amazon, the expectation-gap mechanism applies universally across e-commerce platforms. The same listing claims that generate negative reviews on Amazon will generate negative reviews on Walmart, eBay, Etsy, and direct-to-consumer channels.
The principles are platform-agnostic because they are rooted in human psychology, not platform mechanics. Customers on every platform form expectations from listing copy and evaluate products against those expectations. The specific format differs – Etsy buyers weight craft quality language differently than Amazon buyers weight technical specifications – but the underlying mechanism is identical.
Review prediction accounts for platform-specific buyer expectations. A “handmade” claim on Etsy carries different weight than the same claim on Amazon because Etsy buyers expect artisan quality while Amazon buyers interpret “handmade” more loosely. The prediction adjusts for these contextual differences when generating review forecasts.
For sellers operating across multiple platforms, review prediction identifies platform-specific risks. A listing that works well on Amazon might generate complaints on eBay because eBay buyers have different expectations around shipping time, condition descriptions, or seller communication. Running the same product through platform-specific predictions reveals these differences before they manifest as negative reviews.
The Economics of Review Prevention vs Review Recovery
Consider the cost comparison between preventing negative reviews and recovering from them:
Cost of review recovery (after negative reviews appear):
- Lost sales during low-rating period: significant (conversion drops 30-50% below 4.0 stars)
- Increased PPC costs to maintain visibility: 2-4x normal CPC during recovery
- Product modifications to address complaints: $2,000-$20,000+ depending on issue
- Listing redesign and A+ content revision: $500-$2,000
- Time to accumulate enough positive reviews to dilute negatives: 3-6 months minimum
- Potential need to relaunch under new ASIN: complete loss of review history
Cost of review prevention (before launch):
- Listing copy revision: time investment, minimal cost
- Review prediction testing: fraction of launch budget
- Results: launch with listing optimised for positive reviews from day one
The asymmetry is striking. Prevention costs a fraction of recovery and produces better outcomes because you never enter the negative-review spiral. Once negative reviews appear, they influence subsequent reviewers through priming effects – shoppers who read existing negative reviews are more likely to notice and report the same issues, creating a self-reinforcing pattern that is extremely expensive to break.
Smart product pricing strategy accounts for review risk. A product priced aggressively needs an even more accurate listing because budget buyers have less tolerance for any gap between expectation and delivery. Premium-priced products have slightly more latitude because buyers expect to pay more for quality – but also hold higher expectations overall.
Building a Review-First Listing Strategy
A review-first approach inverts the traditional listing development process. Instead of writing the most compelling marketing copy and hoping reviews will be positive, you start with the question: “What reviews do I want to receive?” and work backward to the listing copy that will generate them.
The framework has four components:
1. Define your target review profile. What rating do you need to compete in your category? What positive themes do you want reviewers to mention? What complaints are acceptable (every product has trade-offs) versus which are unacceptable (anything that suggests the product does not work as described)?
2. Audit your product honestly. What does it actually do well? Where are its genuine limitations? What are the trade-offs you have made on cost, size, features, or materials? This audit becomes the truth baseline against which listing claims are evaluated.
3. Write claims that match reality. For every bullet point and title element, ask: “If 100 customers test this specific claim, what percentage will agree?” If the answer is not above 90%, the claim needs revision. This does not mean writing boring copy – it means writing specific, confident copy that your product can actually support.
4. Predict and iterate. Run the listing through review prediction. Check whether the predicted reviews match your target profile. Revise any claims generating predicted complaints that do not match your acceptable trade-off list. Repeat until the prediction meets your target.
This approach requires more upfront work than the traditional “write marketing copy and launch” method. But it produces listings that perform better on every downstream metric – conversion, ranking, review accumulation, and long-term profitability – because they generate satisfied customers from the first sale.
Your unique selling proposition should be the foundation of this strategy. When your listing leads with genuine, verifiable differentiators rather than generic quality claims, reviews naturally reflect those real strengths rather than disappointment with unmet generic promises.
Frequently Asked Questions
How accurate is AI review prediction compared to actual customer reviews?
Validation testing shows a 0.30 star average error rate for overall rating prediction and 62% overlap between predicted complaint topics and actual negative reviews. This means predictions are typically within a third of a star of reality, and nearly two-thirds of the specific issues flagged by the prediction appear in real reviews. The accuracy is sufficient to identify listings heading for trouble and guide specific revisions.
Can review prediction work for products that do not exist yet?
Yes – and this is one of its most valuable applications. If you have a product specification and a draft listing, review prediction can forecast what reviews would look like before you commit to manufacturing. This lets you identify expectation gaps between your planned listing and your planned product at the concept stage, when changes are cheapest.
Does this replace the need for actual product quality?
No. Review prediction optimises the relationship between listing claims and product reality – it does not substitute for product quality. A genuinely defective product will receive negative reviews regardless of how the listing is written. What prediction prevents is the scenario where a good product receives bad reviews because the listing set unrealistic expectations.
How does review prediction handle different customer segments?
AI shoppers are calibrated to represent the likely buyer demographic for the product’s price point and category. A $200 kitchen appliance attracts different expectations than a $20 one. The prediction accounts for who is likely to buy the product, not a generic “average consumer.” This matters because the same claim can generate positive reviews from budget buyers and negative reviews from premium buyers.
What product categories does review prediction work best for?
Review prediction works best for products where listing claims create testable expectations – which covers most physical product categories on Amazon. Electronics, kitchen appliances, personal care, fitness equipment, and home goods show particularly strong prediction accuracy because they involve specific, measurable claims. Categories with highly subjective evaluation (art, fashion where fit is personal) show somewhat lower accuracy because individual variation in expectations is higher.
How many listing revisions are typically needed?
Most listings require 2-3 revision cycles to reach an optimised predicted rating. The first revision typically addresses the most obvious expectation gaps (vague superlatives, unqualified claims). The second refines specificity in remaining areas. A third may fine-tune language for both accuracy and conversion appeal. Each revision typically improves the predicted rating by 0.2-0.4 stars.
Can review prediction help with existing products that already have negative reviews?
Yes. If your product has accumulated negative reviews, prediction can identify which listing claims are generating ongoing negative feedback. Revising those claims will not remove existing reviews, but it will reduce the rate of new negative reviews. Over time, as positive reviews from better-aligned expectations accumulate, the overall rating improves. This is faster than the alternative of waiting for negative reviews to age out organically.
What is the difference between review prediction and review monitoring?
Review monitoring tells you what customers have already said – it is reactive. Review prediction tells you what customers will likely say based on your current listing – it is proactive. Monitoring is valuable for ongoing management, but prediction is essential for launches and listing revisions where you want to prevent problems rather than respond to them. The ideal approach uses both: prediction before launch, monitoring after.
Same product. Better listing. More sales.
Your product’s reviews are not random. They are a direct function of the expectations your listing creates versus the reality your product delivers. Close that gap before launch – not after the negative reviews have already compounded – and you launch with a structural advantage that compounds in the opposite direction: positive reviews drive ranking, ranking drives sales, sales drive more positive reviews.
About the Author
Andrew Mac is the founder of Saucery, where he builds AI systems that predict how shoppers respond to product listings before real money is spent. His background spans product development, consumer research, and e-commerce optimisation across seven markets. He writes about the intersection of AI prediction and practical product strategy.
Subscribe for F&B Consumer Insights
Data-driven insights on food & beverage consumer preferences, straight to your inbox.